ZK-rollups have long been regarded as the endgame of Ethereum scaling. However, despite their importance to the Ethereum scaling roadmap, there is still widespread uncertainty about several key points:
- What exactly is a zk-rollup?
- What differs between application-specific and general purpose rollups?
- What is a zk-EVM rollup? What do terms like EVM-equivalent and EVM-compatible actually mean, and how do they apply to rollups?
- What is the current state of the zk-rollup ecosystem, and what does that mean for my project?
If you’re a developer looking to understand the next phase of Ethereum scaling, this article will (hopefully) help.
ZK-Rollups
ZK-rollups are made possible by a simple observation: proof systems like STARKs or SNARKs allow for a linear number of statements to be verified with sub-linear processing (e.g. 1000 statements → 10 verifier checks, 10,000 statements → 11 verifier checks). We can use this property to create massively scalable blockchain transaction processing as follows:
- Users lock their assets in a zk-rollup smart contract on L1
- Users submit transactions involving those assets to an L2 sequencer, which gathers them into ordered batches, and generates a validity proof (e.g. a STARK/SNARK) and aggregated state update for each batch
- This state update and proof are submitted to and verified by our L1 zk-rollup smart contract, and used to update our L1 state
- Users can use this L1 state (subject to different data availability mechanisms) to retrieve their assets, allowing for full self-custody and “Ethereum security”

The gas cost of verifying the proof is sublinear to the number of transactions being proven, allowing for vastly more scale compared to direct usage of L1. To understand this process in more granular detail, I’d recommend Vitalik’s Incomplete Guide to Rollups or Delphi’s newly released Complete Guide to Rollups.
Application-Specific Rollups
So far, all production-grade zk-rollups have been what we call “application-specific rollups’’. In an application specific rollup, the rollup supports a fixed number of “state transitions” (e.g. trading) defined by the rollup operator. This is incredibly useful for hyper-optimizing common use cases e.g.:
Application-specific rollups are fantastic at scaling particular, well-understood problems. If your needs as a project can be met by an application-specific rollup, you will likely get better performance, better UX and better pricing for your use case, as their lack of generalisation is a huge advantage. At Immutable, for instance, we are able to eliminate gas fees by subsidising free NFT mints and transfers with a fee on NFT trades — a tradeoff which is only possible due to the predictable nature of the rollup’s state transitions.
However, many projects want to be able to create their own custom logic and smart contracts, independent of the rollup operator, which isn’t possible in an application-specific rollup. Additionally, many DeFi projects need “composability”, or the ability to atomically interact with other projects (e.g. many DeFi projects use Uniswap as a price oracle). Composability is only possible when your rollup supports not only custom code, but native smart contracts which can be deployed by any user. To achieve this, we’ll need to modify the architecture of our zk-rollup to generalize each of our components.

There are several tradeoffs for this increased flexibility: substantially worse performance, less customizability for rollup parameters and higher fees. However, the biggest tradeoff of all has been that there were simply no implementations of general purpose zk-rollups, and certainly none which were capable of production volume. But this is beginning to change:
- StarkNet is currently live on mainnet (albeit in a limited Alpha)
- 3 separate projects (zkSync, Polygon Hermez/zkEVM and Scroll) all announced at ETH CC 2022 that they would be the first “zkEVM” to reach mainnet
These last announcements are worth diving into, because these teams didn’t just announce general purpose rollups, they announced “zkEVM”. What followed was a lot of Twitter fighting around “EVM compatibility”, “EVM equivalency”, “true zkEVM” and which approach was superior. For application developers these conversations are often noise — so the purpose of this blog is to break down these terms, design decisions and philosophies, and to explain their actual impact on developers.
Let’s start at the beginning: what’s the EVM?
Understanding the EVM
The Ethereum Virtual Machine is the runtime environment in which Ethereum transactions are executed, initially defined in the Ethereum Yellow Paper and later modified by a series of Ethereum Improvement Proposals (EIPs). It is composed of:
- A standard “machine” for executing programs, with volatile “memory” for each transaction, persistent “storage” which transactions can write to and an operating “stack”
- ~140 priced “opcodes” which perform state transitions in this machine
Some example opcodes for our virtual machine:
- Stack Operations — PUSH1 (adds something to the stack)
- Arithmetic Operations — ADD (adds numbers), SUBTRACT
- State Operations — SSTORE (store data), SLOAD (load data)
- Transaction Operations — CALLDATA, BLOCKNUMBER (return information about the currently executing transaction)
An EVM program is just a series of these opcodes and arguments. When these programs are represented as one continuous block of code, we call the result “bytecode” (usually represented as a long hexadecimal string).
By putting a large number of these opcodes together into a sequence for execution, we can create arbitrary programs. Ethereum uses a custom virtual machine, rather than adapting an existing VM, because it has unique needs:
- Every operation must have a “cost” to prevent abuse (as all nodes run all transactions)
- Every operation must be deterministic (as all nodes must agree on the state after transaction execution)
- We need blockchain-specific concepts (e.g. smart contracts, transactions)
- Some complex operations must be primitives (e.g. cryptography)
- Transactions must be sandboxed, with no I/O or external state access
The EVM was the first Turing-complete blockchain VM, released in 2015. It has some design limitations, but its massive first mover advantage and subsequent broad adoption has created a huge differentiator for Ethereum — it is by far the most battle-tested piece of smart contract infrastructure in the entire space.
Due to Ethereum’s dominance, many later blockchains have adopted this runtime environment directly. Polygon and BNBChain, for instance, are direct forks of Ethereum, and therefore use the EVM as their run time. It’s worth noting that the EVM is not set in stone, and is frequently modified in upgrades like EIP1559. As other blockchains take time to update, or have diverged from Ethereum in several places, they are often running a slightly outdated version of the EVM and can struggle to keep pace with changes — a fact which can frustrate core Ethereum developers.
Ethereum Compatibility
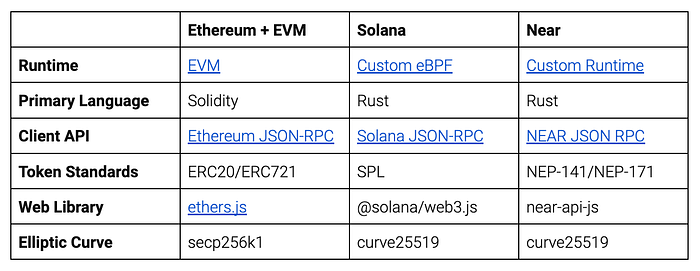
However, what people refer to as being an “EVM chain” usually extends beyond just mirroring this runtime environment. There are several major specifications which began on Ethereum and have become de facto global standards:
- Solidity (a high level language which compiles into EVM bytecode)
- Ethereum’s JSON-RPC Client API (a specification for interacting with Ethereum nodes)
- ERC20/ERC721 (Ethereum token standards)
- ethers.js (a web library for interfacing with Ethereum)
- Ethereum’s cryptography (e.g. keccak256 as a hash function, ECDSA signatures over secp256k1)
Technically, your chain could have an EVM runtime without supporting some or all of the above. However, compliance with these standards makes it substantially easier to use Ethereum tools on your new chain. An excellent example is Polygon, which in addition to using all the above tools, is able to run a forked version of Etherscan (Polygonscan), use Ethereum developer tools like Hardhat, and be supported as a different Ethereum “network” in wallets like Metamask. Tools like Nansen and Dune all initially target Ethereum, and therefore adding support for new EVM blockchains is simple. New wallets, new NFT marketplaces — if the only difference between Ethereum’s interface and your chain’s interface is the chain ID, you’ll likely be the first and easiest addition. With that said, these tools are built for Ethereum — as soon as you start modifying your blockchain (e.g. bigger blocks, faster block times), you run the risk of breaking them. There’s no such thing as perfect compatibility.
Nevertheless, the amount of tools and applications which target Ethereum specifications creates a huge incentive for new blockchains to just mirror Ethereum standards. Any blockchain which does not support the above specifications is automatically behind when it comes to developer tooling, and risks falling further behind as the EVM ecosystem grows.
My belief is that the term “EVM compatible” is actually insufficient for the network effect being described here — what we’re actually describing is “Ethereum compatibility”, and extends way beyond the smart contract execution environment to the entire Ethereum ecosystem and toolset.
To combat this, non-EVM blockchains like Solana have had to create entirely parallel ecosystems, which reduces their velocity and makes it harder to attract existing developers. However, not needing to comply with these standards does give non-EVM blockchains the ability to make more fundamental changes to the Ethereum toolset and thereby differentiate themselves from Ethereum more aggressively. It is very simple to create an EVM blockchain — but why would anyone use yours over one of the literally hundreds of other “fast EVM blockchains”. If you can get over the hump of needing to build out a successful parallel chain and ecosystem, Solana has shown that a) you can attract fantastic native applications (e.g. MagicEden, Phantom) and b) EVM-origin projects will still support you if the commercial incentive is sufficient (e.g. Opensea adding Solana support).
ZK-EVM
Public general purpose rollups all share a common goal: onboard developers and users to generate network effects as quickly as possible. This requires a combination of creating the most performant rollup technology, having the best BD team and doing the earliest or most effective marketing. However, all rollup teams (for the reasons outlined above) are deeply concerned about:
- Migrating existing Ethereum contracts (and developers) to their rollup
- Being supported by existing EVM tooling (e.g. libraries, wallets, marketplaces etc.)
The simplest way to achieve both those goals is to create a “zkEVM”: a general purpose rollup that runs the EVM as its smart contract engine, and maintains compatibility with the common interfaces of the Ethereum ecosystem as described above.
However, this won’t be as easy as forking Geth, as we might when creating a new L1 blockchain from scratch. Our goal is to run EVM bytecode — but ZK-proofs require all the computational statements they are proving to be converted into a very specific format — an “algebraic circuit” which can then be compiled down into a STARK or SNARK. To get a quick intuition on “circuits”, here’s an example (using a more visual boolean circuit as a special case of an arithmetic circuit). In a zkSNARK system based on this simple circuit, our prover wants to convince the verifier that they know inputs (𝑥1 = 1, 𝑥2 = 1, 𝑥3= 0) which produce an output of true. This is a very simple circuit, with a limited number of logic gates — I’m sure you can imagine how many gates are necessary to encode a circuit proving complex smart contract interactions, particularly those involving cryptography!

To understand each step of this compilation process, I recommend Vitalik’s Zero to Hero Guide to SNARKs, as well as Eli Ben-Sasson’s discussion of different proof systems. However, this deeper understanding isn’t necessary for our purposes — just remember that to support EVM computation, we must convert all our EVM programs into these circuits so they can later be proven.
Broadly speaking, there are a few ways to do this:
- Prove the EVM execution trace directly by converting it into a verifiable circuit
- Create a custom VM, map EVM opcodes into opcodes for that VM, then prove the correctness of the trace in that custom environment
- Create a custom VM, transpile Solidity into your custom VM’s bytecode (directly, or via a custom high level language), and prove in your custom environment
Option 1: Proving the EVM Execution Trace
Scroll
Let’s start with the most intuitive: proving the EVM execution trace itself, an approach currently being worked on by the Scroll team (alongside the Privacy Scaling Group at the Ethereum Foundation). To make this work, we’ll need to:
- Design a circuit for some cryptographic accumulator (allowing us to verify that we are reading storage accurately and loading the correct bytecode)
- Design a circuit to link the bytecode with the real execution trace
- Design a circuit for each opcode (allowing us to prove the correctness of reads, writes and computations for each opcode)
Implementing every EVM opcode directly in a circuit is challenging, but because this approach mirrors the EVM exactly, it has substantial benefits for maintainability and tooling support. The following diagram shows that the only theoretical difference between Scroll and Ethereum is the actual runtime environment. However, it’s worth noting that Scroll does not currently support all EVM opcodes through this mechanism, though they intend to reach parity over time.
A fantastic discussion of this was written by the Optimism team, albeit in the context of optimistic rollups. Optimism initially created a custom Optimistic Virtual Machine (OVM) as the execution environment for their rollup. The OVM was “Ethereum-compatible”, which meant it could run modified Solidity code, but several areas of low-level mismatch meant Ethereum tools and complex code frequently needed to be re-written. Due to this, Optimism switched to “EVM-equivalence”, using the exact EVM specification directly, and are developing the first EVM-equivalent fraud proof system. However, optimistic rollups don’t need to worry about circuit or prover efficiency — the right choice for Optimism might not be the right choice for our rollup.
Unfortunately, the EVM’s core infrastructure is not well-suited to zk-rollups. A core measure of rollup performance is the number of “constraints” we need to encode a certain computation into a circuit. In many cases, mirroring the EVM directly introduces massive overhead. For example, the EVM uses 256-bit integers, whereas zk proofs work most naturally over prime fields. Introducing range checks to combat mismatched field arithmetic adds ~100 constraints per EVM step. Ethereum’s storage layout relies heavily on keccak256, which is 1000x larger in circuit form than a STARK-friendly hash function (e.g. Poseidon, Pedersen) — but replacing keccak will cause huge compatibility problems for existing Ethereum infrastructure. Additionally, signatures over the standard Ethereum elliptic curve are extremely expensive to prove and verify compared to SNARK/STARK-friendly elliptic curves. Put simply, proving the EVM directly carries a gigantic computational overhead. While there have been several recent advances here (e.g. polynomial commitments, recursive proofs, hardware acceleration), proving the EVM trace will always be substantially less efficient than proving inside a custom-designed VM, at least until the EVM itself makes changes to become more SNARK-friendly (likely several years away).
Option 2: Custom VM + Opcode Support
This realisation has driven teams to adopt the “EVM-compatible” approach canvassed above: create a custom VM with optimized performance, then convert EVM bytecode directly into bytecode for your VM.
Polygon
One team focused on this approach is Polygon Hermez (recently renamed to Polygon zkEVM). Polygon’s approach is building a zkEVM is “opcode-level equivalency”, which sounds initially similar to the approach taken by Scroll. However, unlike Scroll, Polygon’s alternate runtime (the “zkExecutor”) runs tailor-made “zkASM’’ opcodes rather than EVM opcodes to optimise the EVM interpretation (i.e. reduce the number of constraints vs. proving the EVM directly). The Hermez team describe this as an “opcode based approach”, because the core challenge is recreating every EVM opcode in their custom VM (you can view the code here), so that they can quickly go from EVM bytecode to a verifiable format.
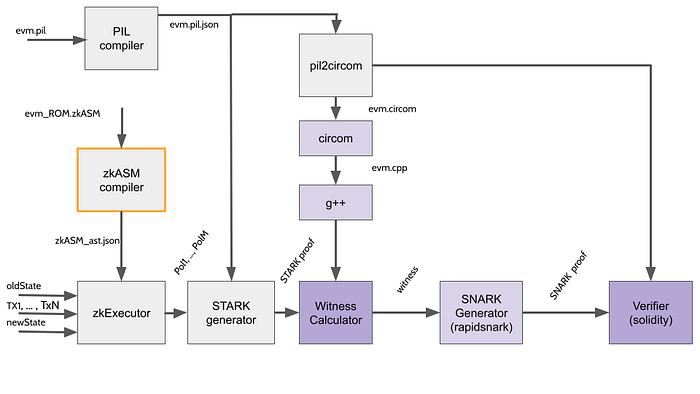
These intermediate steps create an increased surface area for maintenance and potential bugs, but are necessary to enable performant proofs. Ultimately, it’s important to be clear that your programs aren’t running in a zkEVM which mirrors the EVM in a circuit, they’re running in the alternate “zkExecutor” runtime, which is similar but different to the EVM itself. Confusingly, the team has marketed this as both “zkEVM’’ and “EVM Equivalent” — however, because of this custom zkASM interpreter, this rollup is actually “EVM Compatible” per the Optimism definition above.
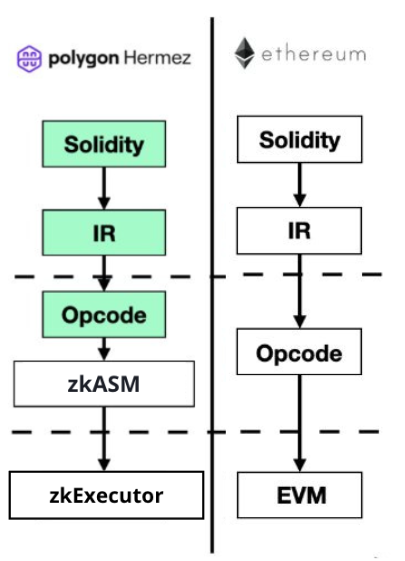
Due to this, it is likely that there will be some incompatibilities with existing L1 applications and tools running on this system, though most Solidity code may be able to be run as is. Polygon have declared compatibility “with 100% of existing Ethereum tooling”, and committed to JSON-RPC compliance, which they reference in their documentation and provide an implementation for here. In practice, this claim is probably aspirational, and something which will rely on Ethereum itself becoming more SNARK-friendly.
Polygon’s approach produces a more performant rollup than Scroll (certainly in the short-mid term), but with:
- Substantially more custom code, as we needed to create zkASM
- The possible requirement for developers to modify their L1 code or tooling frameworks
- Potentially increased drift from Ethereum over time
Option 3: Custom VM + Transpiler
The above solutions invest substantial development time in “making the EVM work for zk-rollups”, prioritising compatibility over long-term performance and scalability. There is another option: create an entire new, purpose built VM, and then add support for Ethereum tooling as an additional layer on top.
StarkNet
This is the approach StarkWare has taken with StarkNet, which is currently the most progressed general purpose rollup. StarkNet runs a custom smart contract VM (Cairo VM), with its own low-level language (Cairo), both purpose built for smart contract rollups. This means StarkNet has no Ethereum compatibility out of the box — as we saw earlier, even opcode-level VM-level compatibility is a potential handbrake on rollup performance.
However, the Nethermind team (in partnership with StarkWare), has created the Warp transpiler, which is capable of transforming arbitrary Solidity code into Cairo VM bytecode. The goal of Warp is to make common Solidity contracts portable to StarkNet — achieving the primary goal of many Ethereum developers when it comes to “EVM compatibility”. In practice, however, there are some Solidity features that are not supported by Warp, including low-level calls (a full list can be found here).
This approach to building a smart contract rollup is maintaining “Solidity-compatibility”: you’re not executing programs inside the EVM, nor maintaining compatibility with any other Ethereum interfaces, but Solidity developers will be able to write code which can be used on your rollup. You can therefore maintain a similar developer experience to Ethereum, without having to compromise the fundamental layer of your rollup — having your cake and eating it too.
However, there are several additional tradeoffs to this approach. The first is that building your own VM is challenging — the Ethereum team has had more than half a decade to iron kinks out of the EVM, and is still frequently making upgrades and fixes. A more custom rollup will allow for better performance, but you will lose the benefit of the collective improvements made to the EVM by every other chain and rollup.
Next, supporting Solidity via transpiler risks a potential loss of composability — if developers are writing contracts in both CAIRO and Solidity, there is a substantial chance that the tooling to support the interface between both will be brittle. So far, the vast majority of StarkNet projects have used CAIRO directly, and they may not be easily composable with future Solidity projects. Finally, and possibly most importantly, the StarkNet team is currently not aiming for compatibility with other Ethereum components — they are rolling their own client APIs, javascript libraries and wallet system, which will force Ethereum-compatible tools to add StarkNet support manually. This is extremely challenging, but not impossible — as outlined above, Solana has been successful enough to have its custom standards respected by some Ethereum tools, but will rely on the ability of the StarkWare team to attract developers who don’t mind rebuilding.
However, if they can do so successfully, the StarkWare team will look to replicate the first mover advantage of the EVM with the first smart contract VM optimised for zk-rollups.
zkSync
Another team adopting this strategy is zkSync. zkSync have created their own VM (SyncVM), which is register-based and defines its own Algebraic Intermediate Representation (AIR). They have then built a specialized compiler to compile Yul (an intermediate language which can be compiled to bytecode for different EVM versions, think a lower-level Solidity) into LLVM-IR, which they then compile into instructions for their custom VM. This is similar to the approach taken by StarkWare, but theoretically provides more flexibility around the base language (though currently only Solidity 0.8.x is supported). The zkSync team originally created their own CAIRO-like language (Zinc), but have pivoted the majority of their efforts to focus on the Solidity compiler to allow a simpler migration for L1 developers. In general, their strategy is to reuse more of the Ethereum toolset than StarkNet — I’d expect their client APIs etc. to be more “Ethereum compatible” as well.
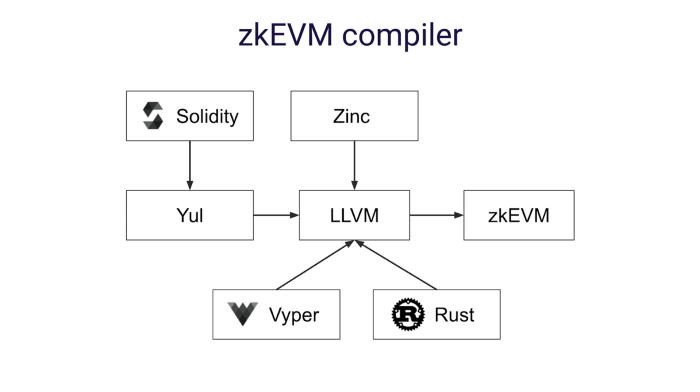
zkSync takes advantage of this custom VM to deliver non-EVM-compatible features like Account Abstraction, which has long been a goal of the core Ethereum protocol. This is a great example of the benefit provided by a custom VM — you don’t have to wait for Ethereum to build new features!
Putting everything together, you can clearly see the different strategies followed by each of the teams:
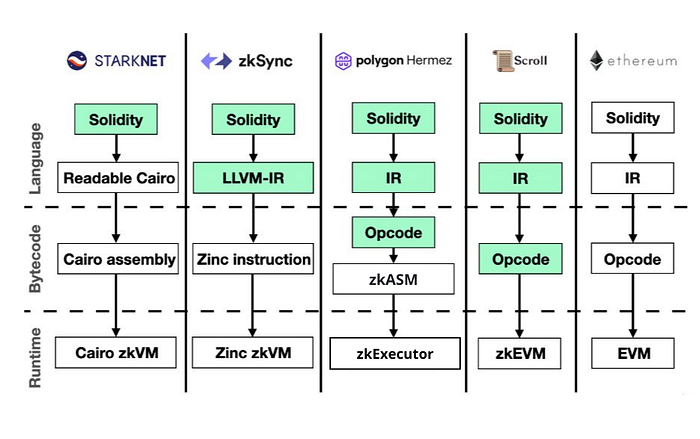
Vitalik’s zkEVM Types
Vitalik Buterin’s blog on zkEVMs highlighted the fundamental dilemma currently facing rollup teams: the EVM wasn’t built for “verifiable” programs. In fact, as we’ve shown through the analysis above, the more compatible you seek to be with Ethereum, the less performant your program in “verifiable format” will be. Vitalik identified several broad categories for general purpose rollups based on their degree of compatibility with existing EVM infrastructure:
The only extension I’d make to his thesis is to note that even within each “type” there is a significant degree of variability — we’re dealing with a spectrum, not fully segmented categories. A Type 3 rollup which makes a single, small change to the application layer has more common with a Type 2 rollup from a developer experience perspective than a Type 3 rollup which has made wholesale changes to the application layer, but without technically introducing a new VM and becoming Type 4.
Current State of Smart Contract Rollups
Given the detail required to understand the above, it’s no wonder we’ve invented a bunch of confusing language around Ethereum compatibility. In truth, no zk-rollup perfectly mirrors the behavior of the EVM in all circumstances — it’s all a matter of degree, and the detailed choices made by each team will end up mattering most when it comes to maintainability and performance, rather than compatibility alone. My opinion is that the following definitions are clearest and most consistent:

It is crucial to understand that none of the above approaches are inherently superior — it’s a categorisation, not a hierarchy. They all make different tradeoffs: easier to build, maintain and upgrade, more performant, more easily compatible with existing tools. Ultimately, the leading rollup will also be determined by better distribution and marketing, rather than pure technical capability. With that said, there’s undoubtedly a substantial advantage to making the right fundamental technical decisions. Will Scroll’s zealous commitment to the EVM specification enable them to easily respond to any EVM upgrades? Will another team’s more pragmatic approach help them get to market more quickly? Will StarkWare’s custom VM + transpiler approach prove a more solid foundation for long-term scale? Will another team end up learning from the mistakes which the first movers in this space will undoubtedly make and beat them to the punch? Ultimately, the beauty of the current moment in Ethereum development is that we have different teams pushing towards a common goal with substantially different approaches.
But before we get carried away, it’s also appropriate to be sober-minded about the current readiness of smart contract rollups. Every team has a strong incentive to market themselves as “just about to take over the world” — but there will be no “production-grade” smart contract rollups on Ethereum until the end of 2022 at the earliest, and many of these teams will not be ready until deep into 2023. Based on StarkNet’s journey, we should expect at least a year of iteration from the point a rollup hits testnet, before that rollup is ready to support consistent production-grade volume on mainnet.
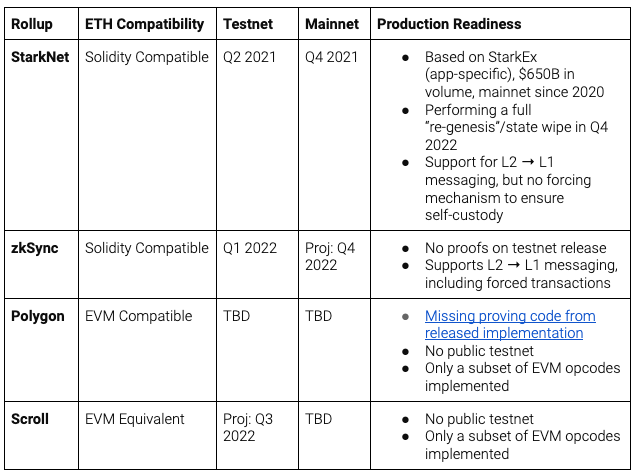
Due to this immature state, application-specific rollups remain the strongest options for developers who need scale without compromising Ethereum security. Indeed, even once general purpose rollups are available and more widely integrated, I expect that the performance, customisation and reliability of application specific rollups will remain superior for some use cases (e.g. exchanges, NFT minting/trading) for the foreseeable future.
Additional Rollup Factors
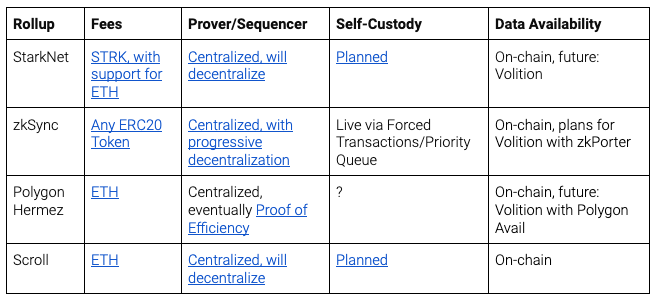
Despite the primary focus of this article, it’s not all about Ethereum ecosystem compatibility vs. performance! There are a number of other factors which impact whether or not you should build on a particular general purpose rollup. I’ll suggest several major additional criteria:
- Fees: will these rollups take a fee in a native token, or in ETH, or in some complex combination of both? Fee structure has a huge impact on user and developer experience, because rollups often require ownership of the fee token to pay for computation.
- Proving & Sequencing: all rollups require an entity which is responsible for ordering transactions and producing proofs. Most application-specific rollups today are “single-sequencer”, which produces higher throughput at the cost of resilience. Most general purpose rollups are initially beginning as single sequencer rollups, but they usually have plans to decentralize this sequencer over time.
- Self-Custody: the core promise of zk-rollups is the ability to unlock scale while preserving Ethereum’s security. However, many general purpose rollups currently don’t have a clear mechanism for the recovery of user assets in the event of a malicious or unavailable sequencer.
- Data Availability: as mentioned in the introduction, self-custody guarantees are subject to the availability of state data in the failure case. However, full data availability introduces additional costs for users, leading to a spectrum of data availability modes. This is already widely used in the application-specific rollup world (e.g. Validiums, Volitions), but each general purpose rollup will need to add this functionality individually.
Summary
Smart contract rollups are an incredibly exciting part of Ethereum’s scaling roadmap. The different tradeoffs made by those rollups in their relationship to the existing Ethereum toolset are an amazing testament to the diversity of Ethereum’s developer ecosystem.
However, current discussions about EVM-compatibility are usually missing the point. From the perspective of developers, all these rollups will support Solidity code. True Ethereum compatibility is a much larger challenge, but one that actually has substantial tradeoffs, which developers should be aware of before committing to a rollup. Currently, most rollup projects are massively “forward selling” — selling the 3+ year vision for their capability, rather than what is possible today (or even in 12 months), which can muddy the waters substantially.
For transparency, I’d like to see each major rollup team provide clearer answers to the following questions:
- What will be the precise differences in the runtime between L1 and L2? Which opcodes will be modified on L2? Will any of the other VM characteristics (e.g. fee structure) be different vs. L1?
- Where is the formal specification of your custom VM, and where is it more performant/less performant than other options?
- How many changes will be made to the other Ethereum interfaces (e.g. client APIs, libraries) by this rollup, which will break Ethereum tools?
- When will this rollup be live on testnet? On mainnet? Able to support sustained production throughput of 1000+ custom contract tps?
- When do you expect to support full self custody for user assets, and what will that look like in the context of a general purpose rollup?
Once these rollups are released on testnet, these questions should be easier to answer. Until then, I’d love to see the teams continue to release more technical details about the exact tradeoffs their solution will make, and how that will impact smart contract and tool developers alike.
With the merge right around the corner, battle-tested application-specific rollups in production, and general purpose rollups hitting mainnet over the next year, the future of Ethereum scaling is right now.
This article would have never been completed without the help of the entire rollup community, and particularly all those who gave pre-launch feedback — I am so grateful! Any remaining mistakes are all mine, and as much of this article has been synthesised from unreleased code, old conference presentations and unfinished documentation, I expect there to be plenty. If you think an update or clarification should be made, feel free to send me a Twitter DM.
If you’d like to work on using the future of rollup technology to onboard the biggest games in the world to Ethereum, Immutable is hiring!
— Alex Connolly, Immutable Co-Founder & CTO
